
INCORPORATING BERT INTO NEURAL MACHINE TRANSLATION review
INCORPORATING BERT INTO NEURAL MACHINE TRANSLATION (ICLR 2020) review
INCORPORATING BERT INTO NEURAL MACHINE TRANSLATION 핵심 요약
ICLR 2020 논문이다.
만든 사람들
중국 과기대 + 마소 + Sun Yat-sen University + Peking University
기여한 점(contribution)
버트를 NMT에 적용해서 context을 이해하는 NMT 구조를 제안하고 공개
배경
버트가 나온건 좋다 이마리야~ pretrain 해서 공개해주니까 적용할 때는 fine tuning만 해주면 모델이 문맥을 잘 이해하고 있음! 근데 버트가 NMT에 대한 적용점은… 아직 확립이 안된 것 가틈… 우리가 다양한 실험을 해보고 만들어서 배포하면 좋겠다~!
저자들이 한 실험
- 시행착호
인코더-디코더 모델에서 인코더를 버트(기학습 모델)로 바꾸고 NMT 학습을 해보는 실험을 주로 해봤는데 사실 큰 성능 성과를 얻지 못함. 기존의 transformer의 인코더에 버트를 넣고, 기본 transformer 구조를 xlm으로 바꾸고 인코더만 버트로 바꾸고… 이런 저런 실험을 해봄. 좀 되다가도 데이터 양이 많은 NMT의 경우 여지없이 기존 SOTA을 넘지못함.
- 버트 + 인코더 디코더 모델
기존의 인코더 디코더 모델을 그대로 두고, 버트 인코더를 따로 붙여서 실험하니까 성능이 올랐음!
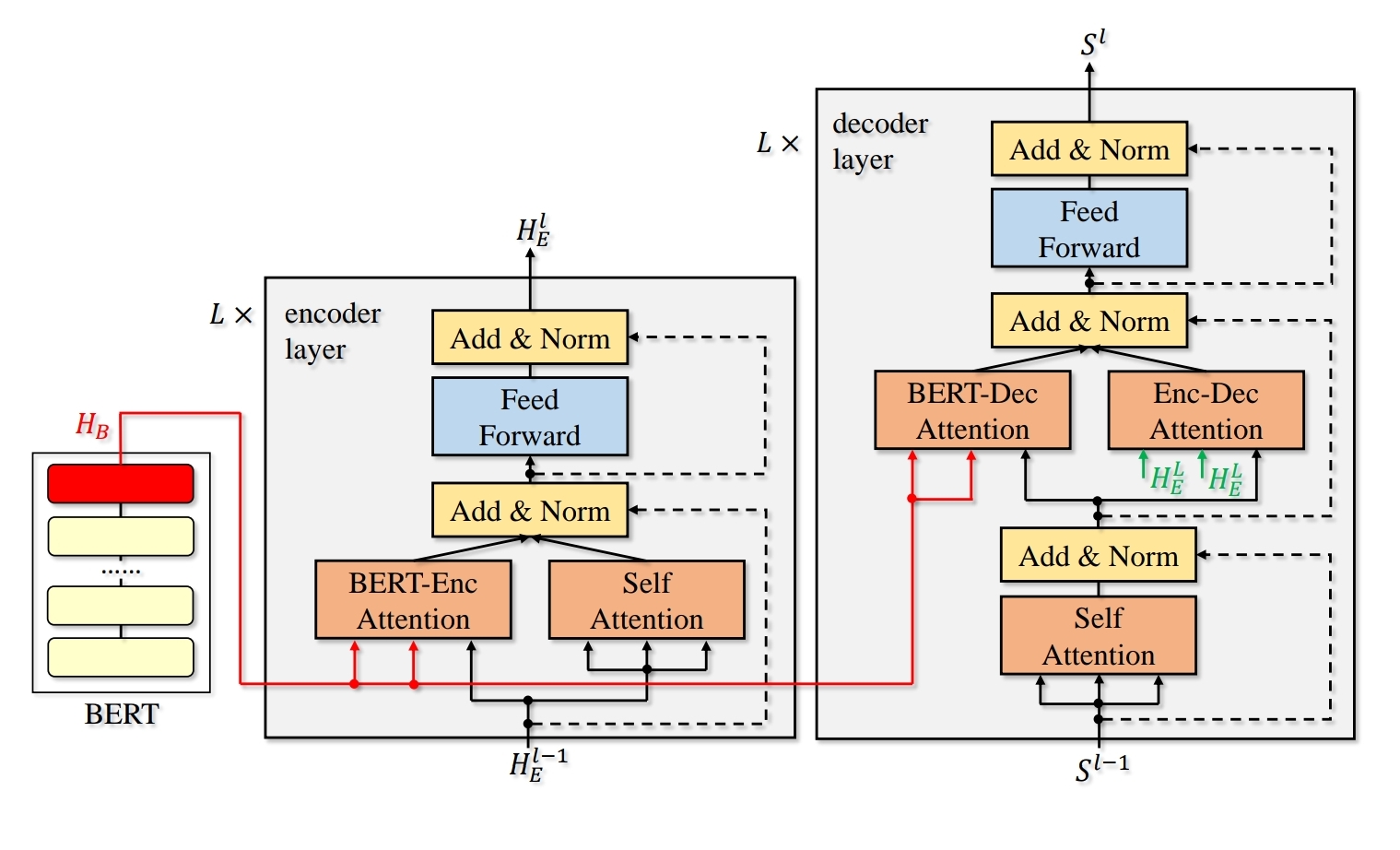
NMT에서 학습할 데이터에 맞는 기학습 버트를 가지고 옴. 데이터를 버트에 통과시켜서 QKV 임베딩을 얻음. 그리고 이제 NMT을 다시 학습함. 이때 버트의 QKV을 attentoin할 때 같이 포함함. NMT 데이터의 q와 버트의 KV을 포함해서 버트 attention 따로, 기존에 transformer에서 수항핸 attention 따로 해서 더함. 나머지 구조는 transformer와 동일하다. 두 attention을 더하는건 그냥… 진짜로 그냥 더해서 1/2 한다 ㅋㅋ
- drop out
drop-net이라고 명명함. 조금 독특하다. 0~1 사이의 확률 값으로 한 레이어의 hidden vector에 적용함. 독특한 점은… 각 노드에서 발생한 확률 값에 따라서… 어떨 때는 bert attention에만 적용하고 어떨 때는 NMT 모델의 attention에만 적용하고 어떨 때는 둘 다 적용 함. inference에는 기존 방법과 마찬가지로 해제시킴.
- supervised learning
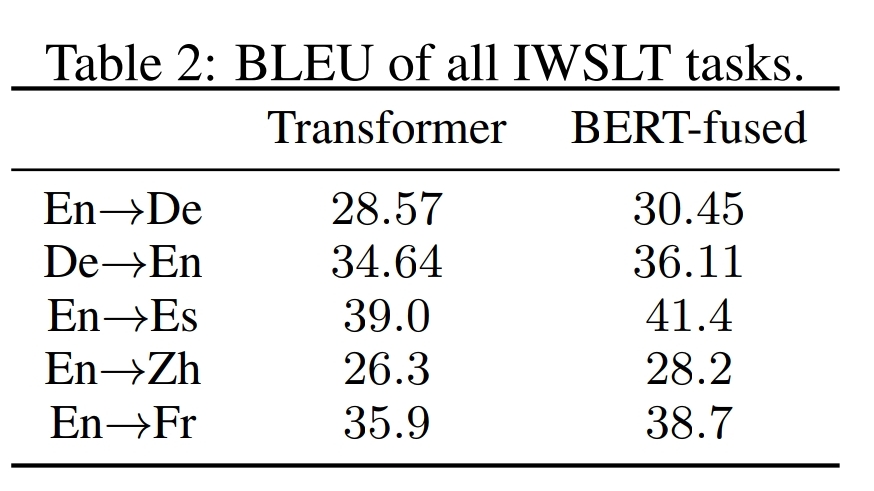
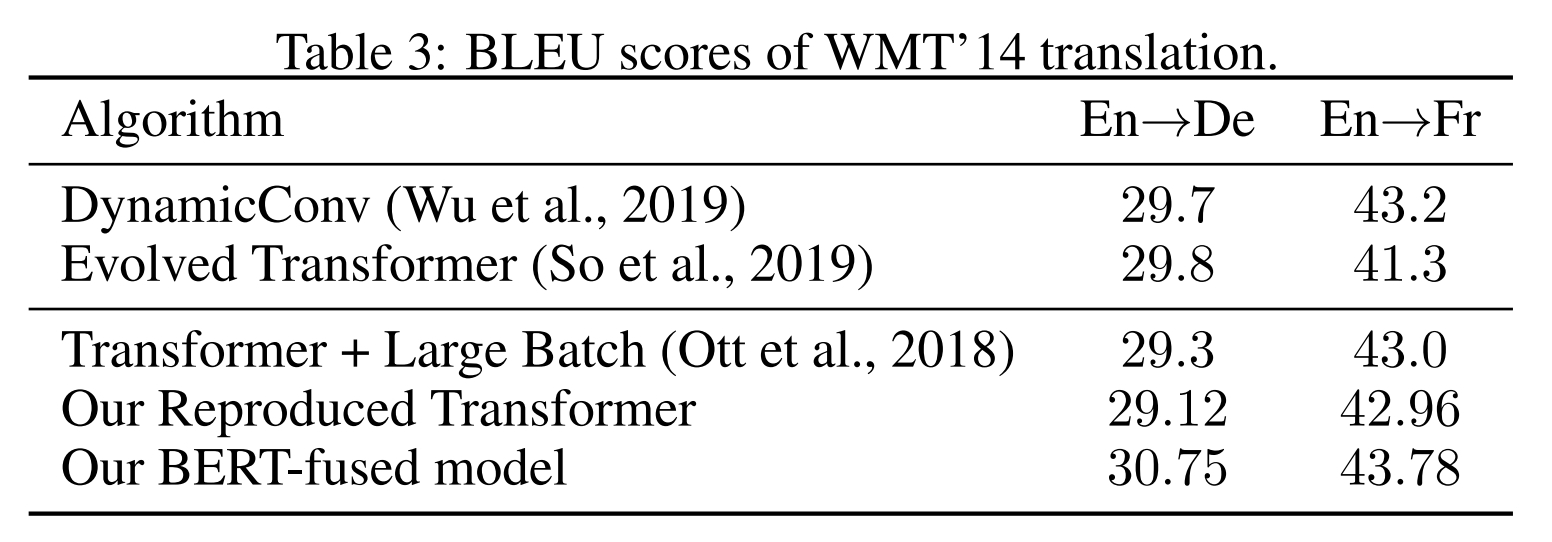
- semi-suvervised learning
여기서 저자들이 말하는 semi-supervised가 몬 소린지 좀 헤맸음… 버트는 기학습 가중치를 그대로 쓴다.
autoencoder라고도 불렸던 방법론을 사용(요즘 말로 하면back translation을 통해서 중간에 hidden representation embedding을 얻는다. https://arxiv.org/abs/1606.04596)해서 pair corpora외에 추가적인 monolingual corpora을 모델에 더 넣어서 학습하는 것을 의미함.
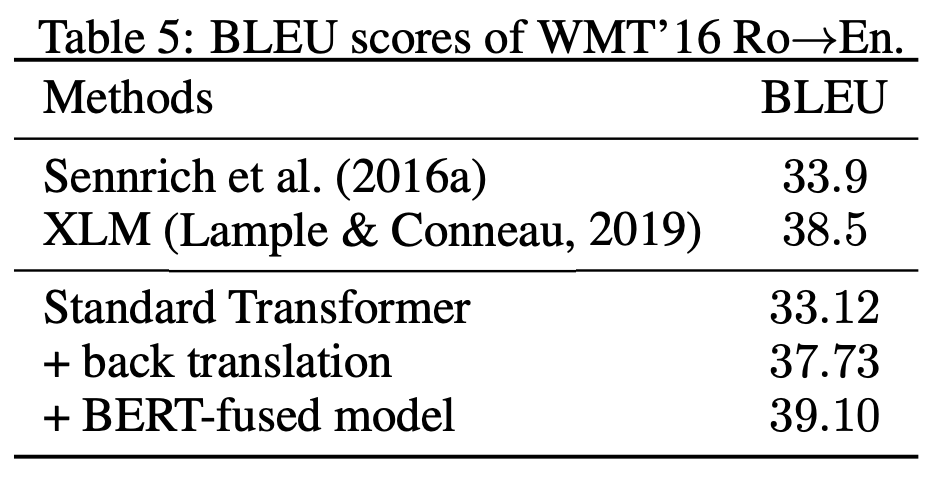
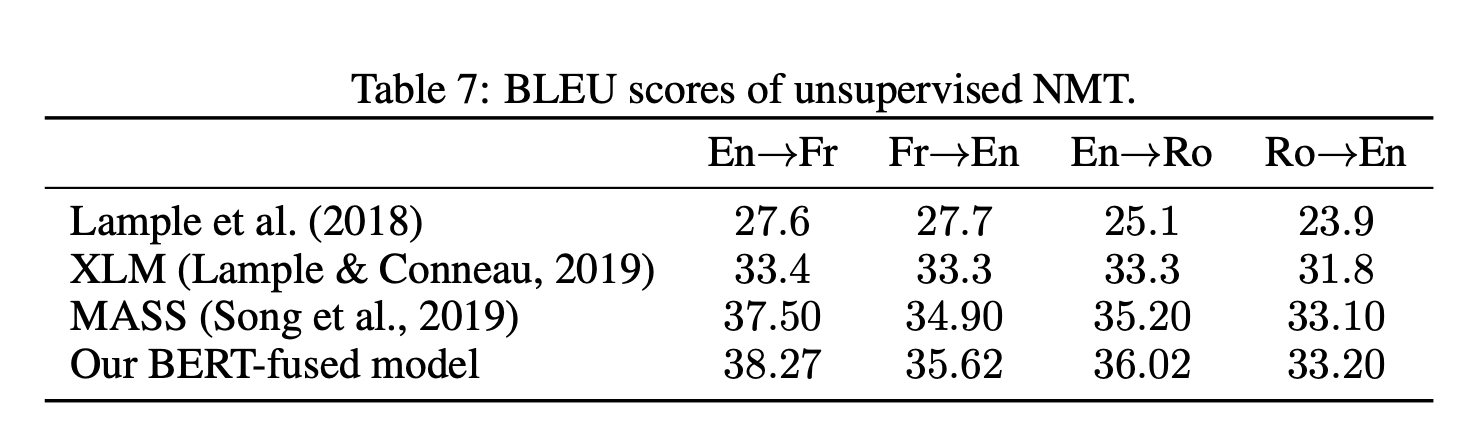
Lample & Conneau (2019)의 citation 848의 Cross-lingual Language Model Pretraining에서 한 세팅에 그대로 비교
inference 속도 감소시키기
경량화
QA 등 다른 task에도 적용해보기
Comments