
ML-model-debugginng
debugging models
CS 229 디버깅 ML 모델 요약 출처: https://www.youtube.com/watch?v=ORrStCArmP4
desired human performance?
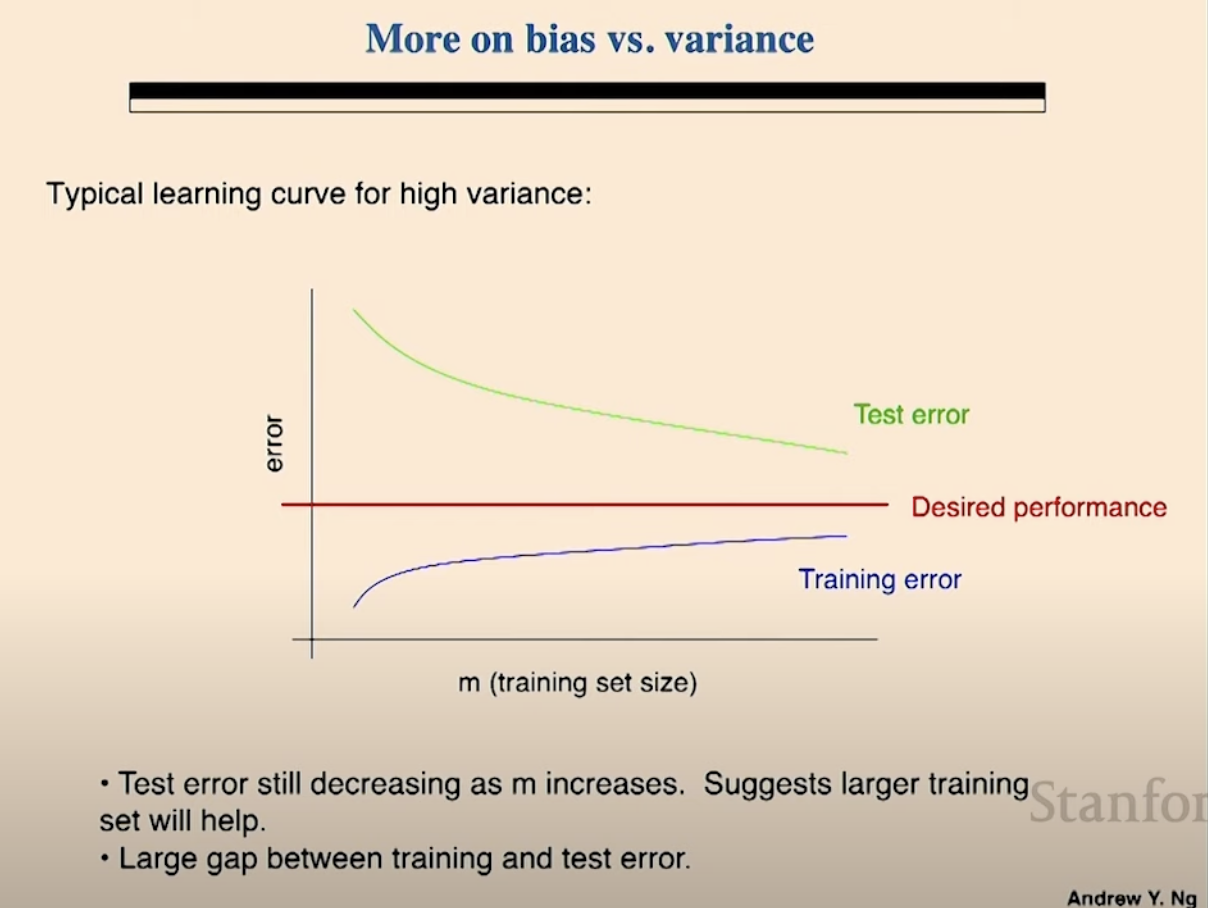
- high variance
- test error
- as training example increases, test error decreases.
- training error
- as training example increases, trainer error increases
- training se이 몇개 있으면 그냥 다 학습해버림. 반대로 너무 많으면 모든 decision boundary를 다 학습할 수 없어서 놓침.
- 두번째 bullet은 명확한 stronger signal이다. 현재 투입된 데이터에서는 trainer error와 test error의 차이가 크다. 그래서 high variance이다.
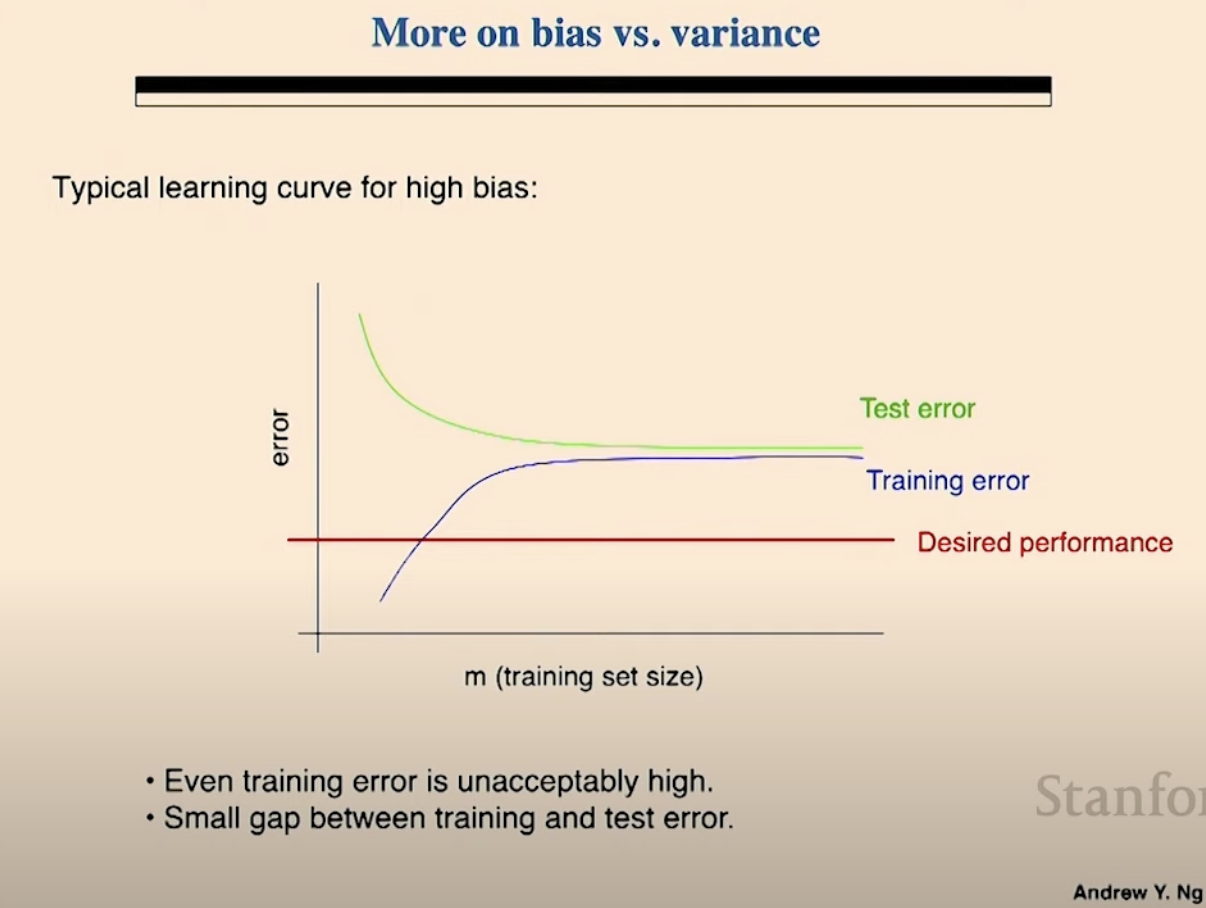
두번째 러닝 커브 with high bias
- training set에서도 잘하고 있지 못하다. not achieving desired performance
- 모델이 직접 본 것도 틀리는 중.
- train와 test error 사이에 gap이 적다.
- 데이터가 얼마나 많든지 간에. training set에서도 학습을 못하면. high bias!
How to fix

- More training data
- assuming iid in training data and test data.
- Try smaller data features
- fixes high variance
- more features → more options to make a decision → smaller change in one feature among many fearues → different results → high variance problem
- less features → less options to make a decision → easier to predict same result with similar data example → less variance
- Try larger data features
- However, with too few features, not enough to make a correct prediction → fail to predict well → high bias
- Different features i.e. email header
- more features → fixes high variance
Donno Higb bais ot high variance before we make it
Make it fast try to implement with the simplest model. Then we know what thie prob is. Then go with complicated model and try with nore advanced data
Quick dirty implementations
Single most powerful tool error analysis high bais and hogh variance
Pattern
Guess whats wrong. Test if the hypo is right.

## High Variance and High Bias 외에도 고민해볼 주제:
- 알고리즘이 수렴하고 있는가? 최적화를 잘 해내고 있는가?
- problem is with optimization of algorithm
- 선택한 함수가 optimize 하기에 알맞은 함수가 맞는가? 이 cost 함수 혹은 이 objective 함수를 선택한 것이 목적 metric을 최적화해주는 것이 맞는가?
- problem is with objective function of the maximization problem
## 진단하기

### problem statement
svm과 log reg가 동일한 task을 수행한다. 성능은 svm이 더 좋은데 log reg을 꼭 쓰고 싶다.
theta svm은 svm으로 학습한 파라미터이고
theta BLR은 baysian log reg으로 학습
목적함수는 weighted accuracy이다. 레이블 마다 다른 가중치를 둔 accuracy.
목적함수의 성능은 svm이 더 좋다.
BLR은 NLL loss에 regularization을 적용 했음.
이 문제를 해결하기 위한 진단
- BLR의 acc가 svm 보다 더 높기 위해서 최적화가 되어야 하는데… loss 선택은 잘 했는데 GD가 어떤 이유에서든지 최적화가 안되고 있다.
- BLR의 loss을 잘못 선택했다. 이 loss는 목적함수 값을 최대화할 수 없다. loss와 obj가 최적화가 되는 방향이 달랐던 것이다!
1과 2는 전혀 다른 문제. 일단 어떤 문제인지 구분해야 한다.

- loss는 제대로 선택한 것이 맞는가?
- svm의 파라미터에 BLR loss을 끼우고 loss 값을 살펴본다..
- fact: a(svm) > a(BLR)
- case 1
- J(svm) > J(BLR)
- svm 파라미터 + BLR에서 사용한 loss에서도 값이 더 좋았다. 즉BLR이 이 loss에서 optimization을 하는데 실패했다는 것. svm이 같은 loss에서도 더 잘했다.
- loss 자체는 잘 설정했다. SVM + NLL도 loss가 낮다. SVM은 자기 나름의 loss 함수로 최적화를 하고서 loss는 계산만 한 것이다. 반면 BLR은 이 loss 자체를 극소화하려고 했다. 그런데도 불구하고 SVM이 이 loss에서 더 잘했다는 말이다. 이 말은 BLR이 어떤 이유에서든지 이 loss을 최소화하는데 실패했다는 말이다. 따라서 BLR에 이 loss을 유지하면서 다른 최적화 알고리즘을 사용해봐야 한다.
- problem is with optimization algorithm
- fact: a(svm) > a(BLR)
- case 2
- J(svm) ≤ J(BLR)
- 이 loss을 BLR이 더 잘 optimize 했다. BLR은 사실 잘 하고 있다는 것! 즉… 이 loss 자체가 metric을 최적화시키지 못한다는 말이다.
- 다른 loss 을 선택해야 함.
- problem is with objective function of the maximization problem
- 정리
- Run gradient descent for more iteration
- 정리
- fixes optimization algorithm
- 현재 loss을 유지하면서 더 많이 학습해본다. 수렴에 실패했으니까 더 많이 시도 - Try Newton’s method
- fixes optimization algorithm
- 동일한 loss을 그대로 사용하면서 최적화하는 방법을 다르게 해본다 - Use different value for lambda
- loss 함수를 바꾸는 것. fixed optimization objective - Try using SVM
- fixes optimization objective
- SVM은 loss 값이 완전히 다름. 그래서 loss을 바꾸는 것.
- svm의 파라미터에 BLR loss을 끼우고 loss 값을 살펴본다..
- test error
Comments