
review ODQR
ODQR paper
그대로 번역한 논문은 많다.
목적: 비유와 함께 쉽게 쉽게 직관적으로 풀어보기.
제목
Latent Retrieval for Weakly Supervised Open Domain Question Answer
함의:
- Latent Retrieval:
- IR과 MRC을 따로 따로 학습하는 것이 아니라 한꺼번에 학습한다
- Weakly Supervised
- pretraining retrieval
- ICT: passege에서 임의 부분을 뺀다. 그 부분이 속한 passage을 맞추는 문제로 pretraining을 한다. 레이블 필요 없는 task.
- BERT
- question encoder, passage encoder, MRC encoder을 모두 BERT 사용. BERT 가 weakly supervised learning으로 pretraining 되었다.
- pretraining retrieval
- Open Domain Question Answering
- 질문자가 어떤 passage에서 답을 찾아야 하는지도 모르는 task.
abstract
이전 논문 DRQA: IR은 학습이 아니라 그냥 TFIDF으로 나오는 것.
IR과 QA을 동시에 학습. 따라서 IR의 결과가 latent으로 매핑되는 것. IR을 ICT으로 pretraining한다. BM25의 IR 보다 성능이 뛰어남.
introduction
IR와 MRC을 downstream task에서 동시에 fine tuning.
IR은 symantic and lexical matching이고 QA는 language understanding이다.
Overview
query가 들어가면 IR에서 top k 문서를 뽑고, 그게 리더로 들어가서 리더가 각 top k에서 주어진 query에 대한 정답을 찾아내는 구조는 DrQA와 동일하다.
고정된 것: query
변하는것: top k의 passage들과 정답 s
ground truth: a.
q에서 s까지 가는 동안의 score을 매긴다. 변하는 모든 변수들(top k passage들과 정답 예측s)에 대해 softmax을 구하고 ground truth에 해당하는 확률과 실제 값1에 대해서 loss을 구해서 학습한다.
그럼 여기서… 어떻게 score을 매기느냐!? 전체 Score는 리트리버 스코어 + 리더 스코어이다.
리트리버 스코어: S_retr(b, q): query가 주어졌을 때 ground truth a가 존재하는 문서 b을 찍을 때의 score.
리더 스코어: S_read(b, s, q). query와 문서 b가 주어졌을 때 각 예측 s의 점수.
전체 경우에 대한 스코어: S_retr(b,q) + S_read(b,s,q)
이 점수들에서 모든 변하는 조합들의 softmax을 해서 ground truth에 해당하는 확률로 loss 계산! ground truth가 있는 문서 b에 해당하는 경로만 정답 확률이 된다!
Inference할때에는 prediction a = TEXT(arg max S(b,s,q))
전체 모든 경우들 중에 가장 확률이 높은 것 선택한다!
S_read는 Squad의 QA에 해당하는 task로 학습. 단지 top k만 주어지는 것! 각 top k에 대해서 모두 실행 함. 배치로 넣어서 할것이다.
어떻게 각 스코어를 구하는지 알아보자.
ORQA
실제 사용하는 모델은 버트다! 버트는 토큰 1개 당 1개의 output hidden representation이 나온다.
리트리버
question을 버트에 넣는다. CLS 만 뽑는다.
passage을 버트에 넣는다. CLS만 뽑는다.
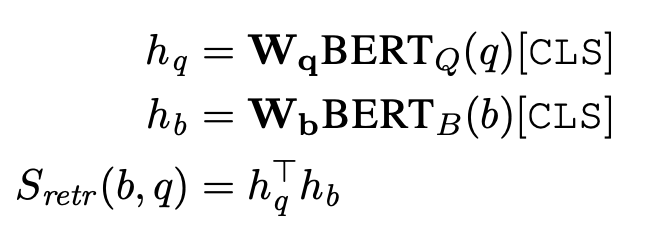
question과 passage을 내적해서 유사도를 구함. passage는 모든 passge을 넣어서 각각의 hidden representation을 구한다. passage에 대해서는 미리 인코딩을 해놓는다. 그래서 fine tuning 할때에는? inference 할때에는? hidden representation들과 question의 인코딩 벡터들만 내적을 구함. 가장 큰 top k을 뽑는다. W는 128 차원이다.
리더
학습할 때
단어의 start 토큰에 해당하는 bert hiden representation
end에 해당하는 hidden representation
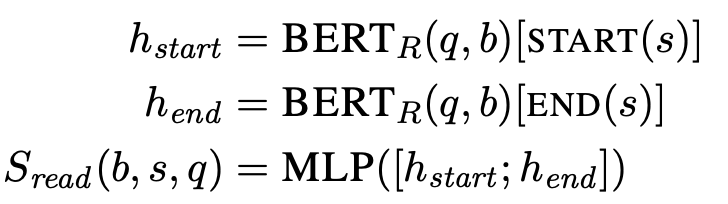
두 hiden representation을 concat 해서 MLP에 넣는다.
MLP?예 넣는게 무슨 말? 그리고 여기서 start와 end가 모든 토큰에 대해서 한다는 말인가? 아니면 label 으로 주어지는 것을 바로 넣는다는 말인가? 근데 label을 바로 넣어버리면… loss 계산할 때 그냥 거기에 weight을 조절하는 것?
코드를 보자. reader 학습.
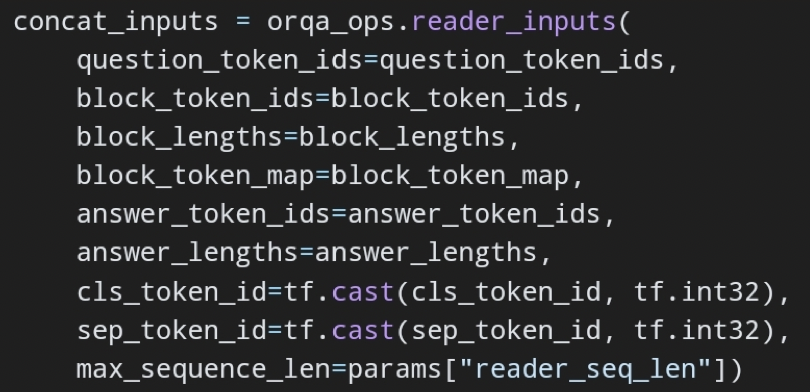


전자가 맞음. 일단 max_span_len을 정해놓고 모든 경우의 수를 만든다. 그리고 그 중에서 가장
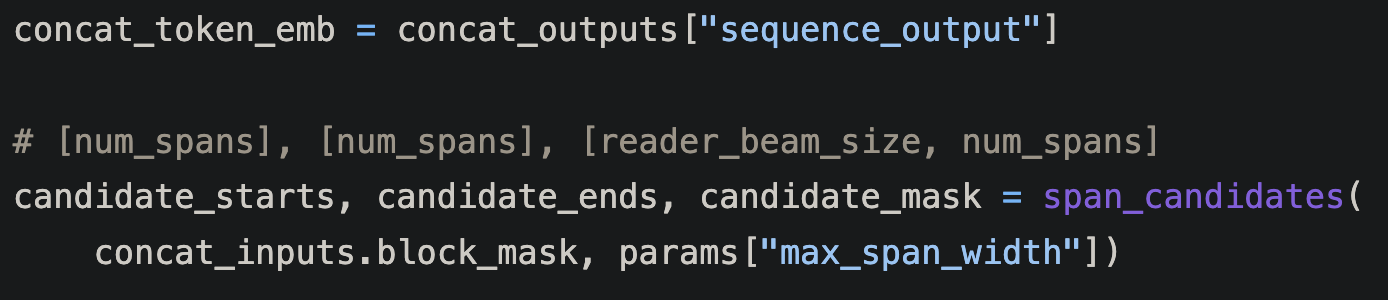
span_candidates으로 모든 span 경우의 수를 받아온다.
output은 버트의 output이다. 각 토큰 마다 hidden token들이 존재한다. 버트의 QA을 따라서 전체 토큰을 S와 E 벡터에 넣고(사실상 단일 NLP: linear 한 다음에 relu 까-아지) softmax 해서 가장 큰 값의 토큰을 선택.

S에 하나 E에 하나 해서 2개. 어차피 1개짜리 레이어는 긴거 하나 해서 반으로 뚝 잘라도 동일하다. 두 start_pos와 end_pos의 동일한 index가 각 span을 이룬다.
S와 E에 대해서 lin 한 결과에서 candidate 토큰을 뽑아냄. QA에서 최종 score은 S와 E의 합이다.

각 span 결과에 대해서 relu로 activate 한다. 그리고 이 중에서 가장 큰 값을 뽑을 거임.

요것은 BERT의 QA task fine tuning task prediction 방법이다.ㅇ

relu는 elementwise operation이다. 그래서 각 노드 1개가 1개의 output이 됨. 그래서? 차원은 여전히 num_candidates, span_hidden_size임.
span_hidden_size을 1개로 실수화. 각 candidate 마다 실수 값 1개만 가지게 되었다! 진짜 스코어가 됨!

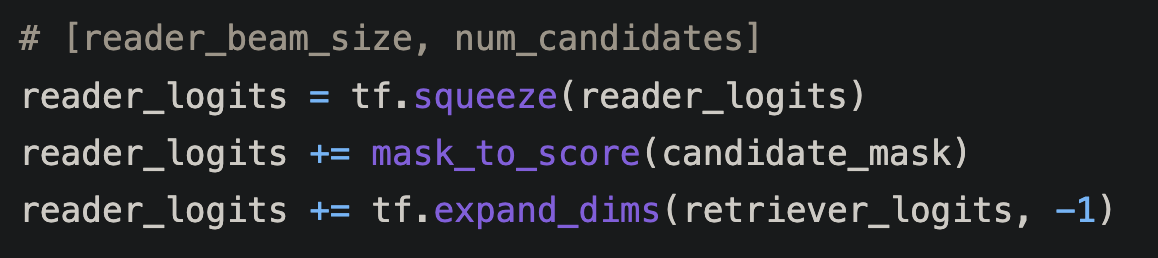
squeeze으로 1 차원을 없앤다. 그래서 이제 각 query에서(아마 주어진 query에서 각 top k의 reader_beam_size개의 문서 마다 num_candidate 마다 1개의 실수 스코어를 가진다.
mask는 span이 max len을 넘어가는 span candidate을 없앰.
이 결과를 reader 모델의 output으로 반환한다.
ICT(Inverse Cloze Task)
리트리버의 pretraining이다. context을 학습시키기 위한 task 이다. passage에서 random 하게 sentence을 뽑아서 그 sentence가 속한 passage을 찾게 하는 문제이다. sentence에 해당하는 passage와 negative passage들 중에서 찾아야 함. 전체 passage의 90은 선택된 문장을 passage에서 제거하고 이 문제를 풀게 한다. softmax으로 문제 풀게 함. 여러개 중에 어느 passage에 속할까?
Inference
ICT을 끝내고 나서 버트를 통해서 passage들을 encoding 시켜 놓는다. 그러면 inference 할때 question을 인코딩 시켜서 유사도 계산해서 top k 만반환해둔다. passage들에 대해서 encoding 안해도 됨.
Learning
리트리버로 나온 topk의 passage가 있다.
그리고 각 passage에 대해서 span_candidate의 모든 score 후보들에 대해서 softmax을 구한다. 거기서 argmax을 취해서 prediction으로 함.
구현에서의 특이점: prediction 자체에서는 softmax을 안넣고 그냥 ㄱ장 큰 span과 리트리버 값을 선택한다. 어차피 softmax을 하면 가장 큰게 크게 되고 거기서 argmax을 하니까 연산을 아끼려고 한 것 같다.

loss을 구할때는 softmax을 함.
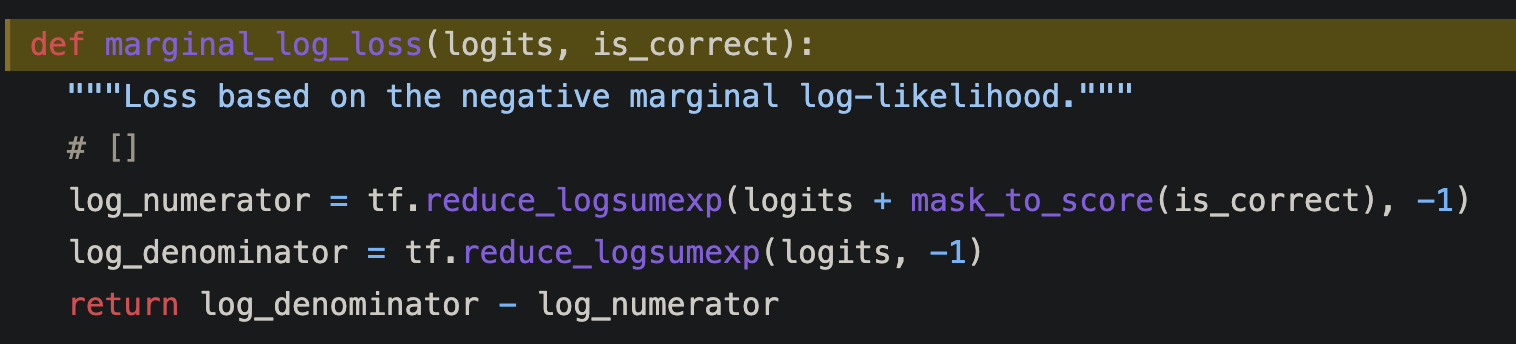



Loss는 query에 대해 ground truth에 해당하는 passage b와 span s에 대한 확률의 negative marginal log liklihood가 됨.
BM25를 능가했다.
아래는 model 코드. 개괄을 알 수 있따.
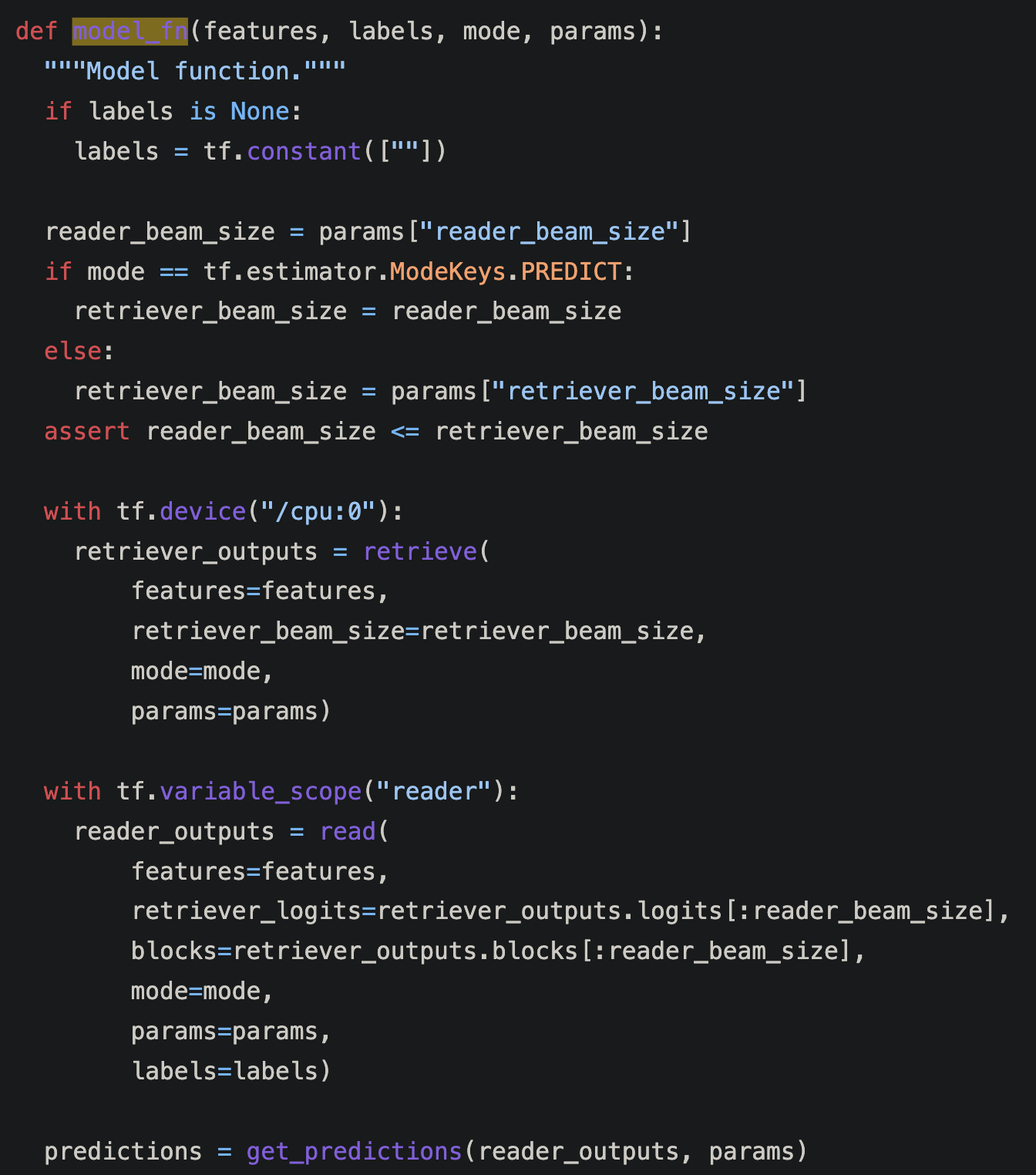
prediction을 따로 구하고.
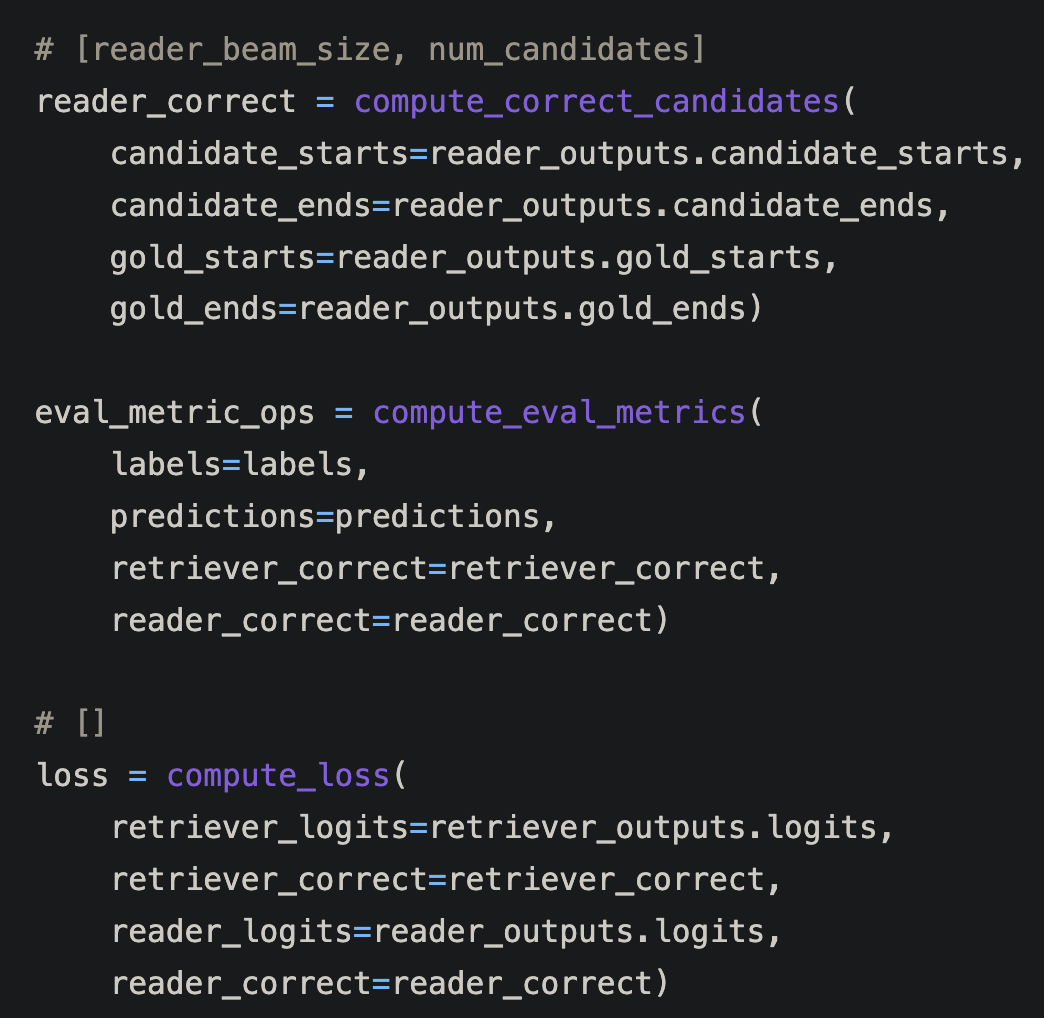
loss 구할 때는 reader correct을 구해서 reader ouptut을 넣는다.
모델 output에서 loss을 반환한다.
loss에 들어가는 logits은 리트리버 logit과 리더 logit이다. automatic differentiation이 될때 리트리버도 편미분, 리더도 편미분. 둘이 따로 따로 된다. loss의 결과 scalar에서만 합쳐진다!
Comments